
选题背景
图像配准、目标识别、三维重建与全景拼接都依赖稳定可靠的局部特征。 对于同一场景的两张图像,拍摄时往往会出现尺度变化、视角变化、旋转以及亮度差异, 如果只使用原始像素进行匹配,算法通常对这些变化非常敏感。SIFT 是经典的局部不变特征方法, 它通过在尺度空间中寻找稳定极值点,并为每个关键点构建具有旋转与一定光照鲁棒性的描述子, 从而在复杂场景下仍能保持较高的匹配成功率
\[1\]。
本次作业选择 SIFT 作为实现对象,目标有两个。第一,完整实现 SIFT 的核心流程,
而不是直接调用 OpenCV 的现成算子;第二,将提取到的特征用于两幅图像的拼接,
验证算法在真实图像上的有效性。围绕这两个目标,本文不仅给出算法原理,
也重点说明与代码 sift.py 对应的实现细节、参数选择与实验结果。
算法描述(重点)
算法原理
尺度空间与高斯差分
要让计算机在不同缩放比例下提取到相同的特征,就必须建立连续的"尺度空间"。Koenderink (1984) and Lindeberg (1994)的研究指出, 在各种合理假设下,唯一可能的尺度空间核是高斯核。
因此,尺度空间函数 $L(x,y,\sigma)$ 定义为变化尺度的高斯函数 $G(x,y,\sigma)$ 与输入图像 $I(x,y)$ 的卷积:
$$\begin{equation} L(x,y,\sigma) = G(x,y,\sigma) * I(x,y) \end{equation}$$其中,二维高斯函数为:
$$G(x,y,\sigma) = \frac{1}{2\pi\sigma^2} e^{-(x^2+y^2)/2\sigma^2}$$为了高效寻找尺度空间中稳定关键点的位置,Lowe 提出使用相邻尺度(即尺度之间相差一个常数因子 $k$)的高斯平滑图像相减,得到高斯差分函数 $D(x,y,\sigma)$:
$$\begin{align*} D(x,y,\sigma) & = (G(x,y,k\sigma) - G(x,y,\sigma)) * I(x,y) \\ & = L(x,y,k\sigma) - L(x,y,\sigma) \end{align*}$$这么做的原因有很多,首先,DoG是一个计算效率很高的办法,因为在任何情况下进行尺度空间描述都需要平滑图像$L$,而$D$可以通过简单的图像减法得到。
其次,DoG 是对尺度归一化的高斯拉普拉斯算子($\sigma^2\nabla^2G$)(LoG)的绝佳近似。Lindeberg(1994)表明,为了真正的尺度不变性,需要使用因子 $\sigma^2$ 对拉普拉斯算子进行归一化。Mikolajczyk(2002)发现,与其他一系列可能的图像函数相比,$\sigma^2\nabla^2G$的最大值和最小值提取的图像特征 最为稳定。DoG 与 LoG 的关系可以用热传导方程来解释(用$\sigma$ 进行参数化):
$$\frac{\partial G}{\partial \sigma} = \sigma\nabla^2G$$$\nabla^2G$ 可以通过对$\partial G / \partial \sigma$的有限差分近似来获得,计算在相邻尺度$k\sigma$和$\sigma$之间的差值:
$$\sigma\nabla^2G = \frac{\partial G}{\partial \sigma} \approx \frac{G(x,y,k\sigma) - G(x,y,\sigma)}{k\sigma - \sigma}$$整理后可得:
$$\begin{equation} G(x,y,k\sigma) - G(x,y,\sigma) \approx (k-1)\sigma^2\nabla^2G \end{equation}$$这证明了相差常数因子 $k$ 的高斯差分函数已经隐式地包含了实现尺度不变性所必需的 $\sigma^2$ 尺度归一化操作。 式中因子 $(k-1)$ 在任何尺度上都为常数,因此不会影响极值位置。当 $k$ 趋近于 $1$ 时,误差将趋于零,但实际上,即使在尺度上差异很大, 近似几乎不会对极值检测产生影响。
一种有效地构造尺度空间的方法如1{reference-type=“ref+label” reference=“fig:dog_theory”}所示。初始图像与不同尺度的高斯核重复卷积,以生成在尺度空间中由常数因子 $k$ 相差的图像序列在左列。 右侧未相邻图像相减得到的高斯差分图像。
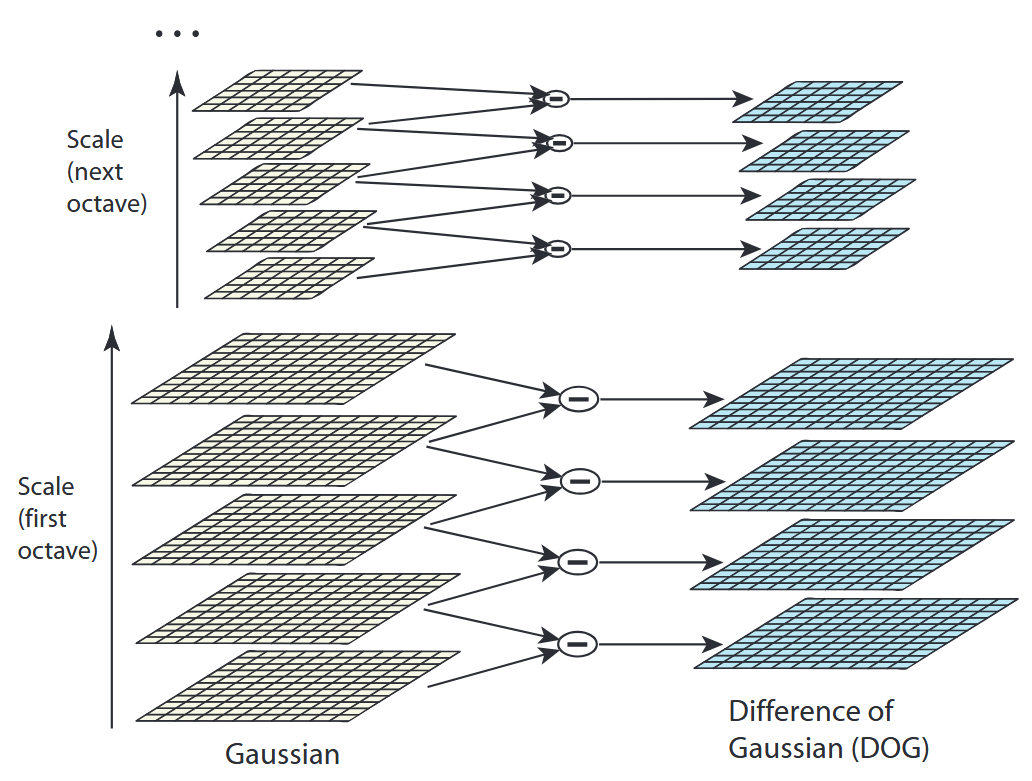
对于尺度空间的每个 octave,初始图像与高斯核重复卷积产生左侧所示的一组尺度空间图像。相邻高斯图像被减去以产生右侧的 高斯差分图像。在每个octave之后,高斯图像被下采样 2 倍,再重复该过程。
由于要在相邻尺度进行比较,那么一个每 octave 含4层的高斯差分金子塔,只能在中间两层中进行两个尺度的极值点检测,其它尺度则只能在不同组中进行。 为了在每 octave 中检测 $s$ 个尺度的极值点,则DoG金字塔每 octave 需 $s+2$ 层图像,而DoG金字塔由高斯金字塔相邻两层相减得到,所以高斯金字塔每 octave 需 $s+3$ 层图像。 Lowe 经过实验发现,当 $s = 3$ 时,特征点的稳定性达到最高。
接下来需要计算每层图像对应的尺寸和尺度。Lowe 规定每过一个 octave,图像的长和宽就需要缩小一半。也就是说,面积会变成上一组的四分之一。 每个 octave 内,图像的尺度应该递增,之前已经定义 $k$ 是相邻两层图像之间的尺度比例常数。每个 octave 需要进行 $s$ 个尺度区间的划分, 即在这个 octave 中我们要检测出 $s$ 个尺度的极值点,因此设定一个 octave 内的 $k$ 应该按照 $k = 2^{1/s}$ 变化。假设初始层的尺度为 $\sigma_0$, 例如,在第一个 octave 的 6 层高斯图像中,$s = 6-3 = 3$,尺度的分布如下:
-
第 1 层:$\sigma_0$ (即 $1.6$)
-
第 2 层:$k\sigma_0$
-
第 3 层:$k^2\sigma_0$
-
第 4 层:$k^3\sigma_0 = 2^{3/3}\sigma_0 = 2\sigma_0$ (即 $3.2$)
-
第 5 层:$k^4\sigma_0$
-
第 6 层:$k^5\sigma_0$
一个 octave 的定义是绝对尺度 $\sigma$ 翻倍(变成 $2\sigma$),所以选择第4层(即 $2\sigma_0$)下采样后作为下一 octave 的初始图像。 $2\sigma_0$ 图像下采样后相对于本层未进行模糊处理的图像的尺度为 $\sigma_0$。然后不断乘新的 $k$,得到该层其他图像。
Lowe 假设相机的原始图像已经自带了 $\sigma=0.5$ 的轻微模糊。为了保留更多高频细节,他先通过双线性插值把原图的长宽放大一倍(此时相对新像素间距 $\sigma=1.0$) ,然后再进行一次高斯平滑,达到基础尺度 $\sigma_0 = 1.6$。论文实验证明 $1.6$ 能提供接近最优的重复率。所以一般选择 $\sigma_0 = 1.6$ 作为初始尺度。
关键点的精确定位与筛选
接下来就是提取极值点,如2{reference-type=“ref+label” reference=“fig:minia_maxima_theory”}所示。离散空间中的局部极值检测在数学上定义了 $D(x,y,\sigma)$ 之后,由于计算机处理的是数字图像, 我们必须在离散的像素网格和有限的尺度层级中去寻找这个函数的极值点 。为了检测 $D(x,y,\sigma)$ 的局部最大值和最小值,Lowe 采用了一种三维的邻域比较法: 以当前正在考察的采样点为中心。
-
把它与当前尺度(同一张图像)周围的 8 个相邻像素点进行比较。
-
把它与上一尺度图像对应位置的 9 个相邻像素点进行比较。
-
把它与下一尺度图像对应位置的 9 个相邻像素点进行比较。
一共需要与周围的 $8 + 9 + 9 = 26$ 个邻居进行比较。只有当该中心点的值严格大于所有 26 个邻居, 或者严格小于所有 26 个邻居时,它才会被选中作为"候选关键点" 。虽然听起来每个点都要比 26 次计算量很大,但 Lowe 在论文中特别指出,这个操作的实际计算成本相当低。 因为在实际代码执行时,绝大多数点在和前几个邻居比较后,就会因为不满足"严格大于或小于"的条件而被迅速淘汰,根本不需要完成全部 26 次比较。
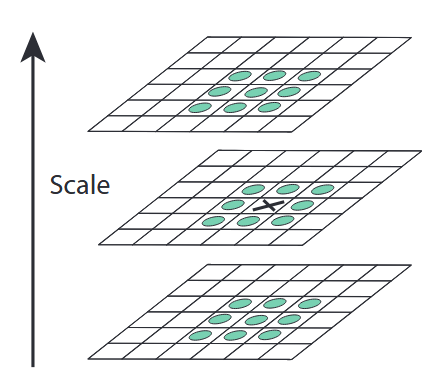
在尺度空间中,候选关键点的提取过程。
通过比较相邻像素找到离散的极值点后,接下来利用泰勒展开进行亚像素级别的精确定位,并剔除不稳定的点。 将原点平移至采样点,对尺度空间函数 $D(x,y,\sigma)$ 进行三元($x, y, \sigma$)二阶泰勒展开:
$$\begin{equation} D(\mathbf{v}) = D(0) + \frac{\partial D}{\partial \mathbf{v}}^T \bigg |_{\mathbf{v}=0} \mathbf{v} + \frac{1}{2} \mathbf{v}^T \frac{\partial^2 D}{\partial \mathbf{v}^2} \bigg |_{\mathbf{v}=0} \mathbf{v} \end{equation}$$这里的参数 $\sigma$ 更确切的说应该是 $s$,即尺度空间的坐标。 $\mathbf{v} = (x, y, \sigma)^T$ 是相对于采样点的偏移量向量。对该式求导并令其为零,即可得到极值的精确偏移量估计 $\hat{\mathbf{v}}$:
$$\begin{equation} \hat{\mathbf{v}} = -\frac{\partial^2 D}{\partial \mathbf{v}^2}^{-1} \frac{\partial D}{\partial \mathbf{v}} \end{equation}$$将求得的 $\hat{\mathbf{v}}$ 代回泰勒展开式,计算极值点处的函数值:
$$\begin{equation} D(\hat{\mathbf{v}}) = D + \frac{1}{2} \frac{\partial D}{\partial \mathbf{v}}^T \hat{\mathbf{v}} \end{equation}$$如果 $|D(\hat{\mathbf{v}})| < 0.03$,则说明该点对比度过低,容易受噪声干扰,予以剔除。
DoG 函数在图像边缘会产生强烈的响应,但边缘点在垂直于边缘的方向上定位非常不稳定。Lowe 借用了 Harris 角点检测的思路
\[2\],通过计算关键点所在位置和尺度下的 $2 \times 2$ Hessian 矩阵 $H$ 来分析主曲率:
$$\begin{equation} H = \begin{bmatrix} D_{xx} & D_{xy} \\ D_{xy} & D_{yy} \end{bmatrix} \end{equation}$$矩阵特征值 $\alpha$(较大值)和 $\beta$(较小值)与主曲率成正比。为了避免直接计算特征值,算法通过计算矩阵的迹和行列式来评估主曲率比值 $r = \alpha / \beta$:
$$Tr(H) = D_{xx} + D_{yy} = \alpha + \beta$$$$Det(H) = D_{xx}D_{yy} - (D_{xy})^2 = \alpha\beta$$
曲率比值关系可化简为:
$$\begin{equation} \frac{Tr(H)^2}{Det(H)} = \frac{(r+1)^2}{r} \end{equation}$$若 $\frac{Tr(H)^2}{Det(H)} \ge \frac{(r+1)^2}{r} \bigg |_{r=10}$ (Lowe 在论文中默认主曲率比值上限 $r=10$)则说明该点为边缘响应点,予以剔除。
方向分配
为了实现旋转不变性,算法需要为每个关键点分配一个基准方向。 在关键点所在的特定尺度$\sigma’$下,得到对应的尺度图像$L(x,y, \sigma’)$。 计算以特征点为中心、以 $3 \times 1.5 \sigma’$ 为半径的窗口内每个像素点的梯度幅值 $m(x,y)$ 和梯度方向 $\theta(x,y)$。
$$\begin{equation} m(x,y) = \sqrt{(L(x+1,y) - L(x-1,y))^2 + (L(x,y+1) - L(x,y-1))^2} \end{equation}$$$$\begin{equation} \theta(x,y) = \tan^{-1}\left(\frac{L(x,y+1) - L(x,y-1)}{L(x+1,y) - L(x-1,y)}\right) \end{equation}$$
随后,使用直方图统计邻域内像素的梯度和方向,形成一个包含 36 个方向区间(bin)的直方图(覆盖 360 度)。 直方图的区间通常被定义为"左闭右开"$[a, b)$,角度映射到对应 Bin 的索引通常是通过向下取整操作来实现的。即
$$Bin\_Index = \lfloor \frac{Angle}{10} \rfloor \pmod{36}$$在统计完所有梯度后,通常会使用一维高斯核对这 36 个 Bin 进行一次滑动窗口平滑,均衡临界位置的梯度。 其次找到最高峰所在的 Bin 时,会取该 Bin 及其左右相邻的两个 Bin(共 3 个点),在这 3 个点上拟合一条开口向下的抛物线。 抛物线的顶点横坐标,就是该关键点最终的主方向角度。剩下达到峰值 80% 以上的局部极值,同样对它进行 3 点抛物线拟合求出精确角度。 然后,在完全相同的 $(x, y)$ 坐标和 $\sigma$ 尺度下,克隆出一个新的关键点,并赋予它这个辅方向角度。
至此,将检测出的含有位置、尺度和方向的关键点,即是该图像的SIFT特征点。
局部图像描述符
Lowe 对这一部分的设计深受 Edelman 等人关于初级视觉皮层中"复杂神经元(Complex neurons)“模型的启发。复杂细胞对特定方向和频率的梯度有响应, 但允许梯度在较小的感受野内发生空间位置的偏移。从某种程度上讲,SIFT 特征描述符就是对复杂细胞响应的模拟。
通过以上的步骤已经找到了SIFT特征点位置、尺度和方向信息,下面就需要使用一组向量来描述关键点,也就是生成特征点描述子,这个描述子不但包括关键点, 也包含关键点周围对其有贡献的像素点,并且描述符应该有较高的独特性,以便于提高特征点正确匹配的概率。
确定计算描述子所需的图像区域特征描述子与特征点所在的尺度有关,因此,对梯度的求取应在特征点对应的高斯图像上进行。 将关键点附近的邻域划分为$d×d$(Lowe 建议$d=4$)个子区域,每个子区域作为一个种子点,每个种子点有8个方向。
每个子区域的物理尺寸与关键点的尺度 $\sigma$ 挂钩。具体而言,为每个子区域分配的实际边长为 $3\sigma$。 由于整个描述符由 $d \times d$ 个子区域构成,为了兼顾边界插值所需的外扩($d+1$)以及最极端 $45^\circ$ 旋转时的对角线冗余 ($\sqrt{2}$),实际计算所需图像区域半径 $R$ 为:
$$\begin{equation} R = \frac{3\sigma \times \sqrt{2} \times (d+1)}{2} \end{equation}$$其中 $\sigma$ 为关键点的当前尺度,$d=4$ 为子区域划分数量。该半径保证了在旋转 $45^\circ$ 的最极端情况下,采样窗口仍然能够完整覆盖所有子区域, 为后续的双线性插值预留了足够的边界余量。
坐标旋转与梯度重采样
以关键点为中心,在最接近该关键点尺度的平滑图像 $L(x,y)$ 上划定一个半径为 $R$ 的圆形采样窗口。为了实现绝对的旋转不变性, 必须将采样窗口的坐标轴根据关键点的主方向 $\theta$ 进行反向旋转。对于窗口内的任意采样点 $(x,y)$(以关键点为中心), 旋转后的坐标 $(x’, y’)$ 为:
$$\begin{equation} \begin{bmatrix} x' \\ y' \end{bmatrix} = \begin{bmatrix} \cos\theta & -\sin\theta \\ \sin\theta & \cos\theta \end{bmatrix} \begin{bmatrix} x \\ y \end{bmatrix} \end{equation}$$旋转后,所有的梯度数据都被映射到了一个与图像绝对旋转无关的局部坐标系中,3{reference-type=“ref+label” reference=“fig:descriptor_theory”} 左半部分展示了这一过程。
梯度幅值与方向的计算
在旋转后的坐标系中,计算每个采样点的梯度幅值 $m(x’,y’)$ 和梯度方向 $\phi(x’,y’)$(注意此处 $\phi$ 是相对于旋转后坐标系的局部方向)。 由于旋转后的坐标 $(x’, y’)$ 通常是浮点数,无法直接索引图像像素,因此需要采用双线性插值从原始图像 $L$ 中获取该点的像素值, 再通过有限差分计算梯度:
$$\begin{align} m(x',y') & = \sqrt{(L(x'+1,y') - L(x'-1,y'))^2 + (L(x',y'+1) - L(x',y'-1))^2} \\[4pt] \phi(x',y') & = \tan^{-1}\left(\frac{L(x',y'+1) - L(x',y'-1)}{L(x'+1,y') - L(x'-1,y')}\right) \end{align}$$其中 $L(x’,y’)$ 表示通过双线性插值在浮点位置 $(x’,y’)$ 处获得的灰度值。
高斯加权
为了让距离关键点中心较远的梯度对描述符的贡献减小(以提高对位置偏移的鲁棒性),算法使用一个以关键点为中心的高斯权重函数对梯度幅值进行加权。 该高斯窗口的尺度 $\sigma_w$ 取子区域宽度的一半,即 $\sigma_w = 0.5 \times 3\sigma = 1.5\sigma$。 对于位置 $(x’,y’)$ 处的采样点,其加权后的梯度幅值为:
$$\begin{equation} m_w(x',y') = m(x',y') \times \exp\left(-\frac{x'^2 + y'^2}{2\sigma_w^2}\right) \end{equation}$$3{reference-type=“ref+label” reference=“fig:descriptor_theory”} 中以重叠的圆形示意了高斯权重的分布范围。
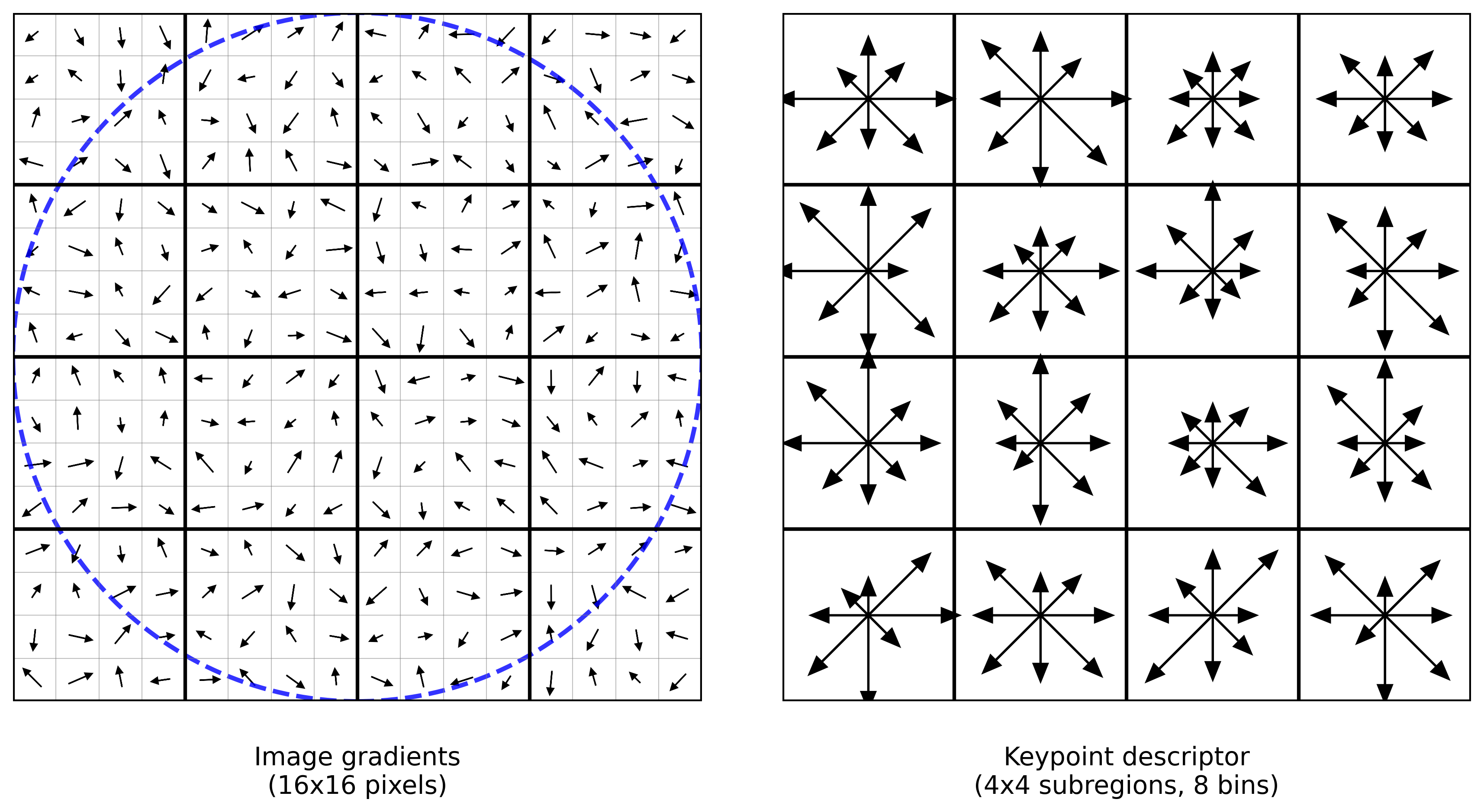
左图:将关键点周围 16 \times 16 的采样窗口划分为 4 \times 4 个子区域,每个子区域统计 8 个方向的梯度直方图, 最终形成 4 \times 4 \times 8 = 128 维描述符向量。高斯窗口(重叠圆圈)用于降低远离中心像素的权重。 右图:每个子区域的 8 方向梯度直方图,箭头长度表示该方向上的梯度累加和。
三线性插值分配
将旋转后的采样窗口划分为 $d \times d = 4 \times 4$ 个子区域,每个子区域的大小为 $3\sigma \times 3\sigma$。 每个采样点的加权梯度幅值 $m_w(x’,y’)$ 需要按照三线性插值的方式分配到相邻的子区域和方向区间中。
具体而言,对于每个采样点,根据其相对于 $4 \times 4$ 子区域网格的浮点坐标 $(x_r, y_r)$ 以及梯度方向 $\phi$, 将其幅值按距离权重分配到相邻的 2 个子区域行、2 个子区域列以及 2 个方向区间(共 $2 \times 2 \times 2 = 8$ 个 bin)中。 分配给某个特定 bin 的权重为:
$$\begin{equation} w = m_w \times (1 - d_x)(1 - d_y)(1 - d_\phi) \end{equation}$$其中 $d_x, d_y, d_\phi$ 分别为采样点在该维度上与相邻 bin 中心之间的距离。这种平滑分配机制有效避免了直方图的突变, 提高了描述符的稳定性。
生成描述符向量
经过三线性插值后,每个子区域生成一个包含 8 个方向区间(每 $45^\circ$ 一个区间)的梯度直方图。将这些直方图按顺序排列, 形成一个 $4 \times 4 \times 8 = 128$ 维的特征向量 $\mathbf{f} = (f_1, f_2, \dots, f_{128})$。 这个向量即为 SIFT 特征点的最终描述符。
归一化与抗光照变化处理
为了减少光照变化(如亮度偏移和对比度变化)对描述符的影响,需要对 128 维向量进行归一化处理。 首先将向量归一化为单位长度:
$$\begin{equation} \mathbf{f}' = \frac{\mathbf{f}}{\|\mathbf{f}\|_2} = \frac{\mathbf{f}}{\sqrt{f_1^2 + f_2^2 + \cdots + f_{128}^2}} \end{equation}$$但单位归一化只能消除线性光照变化(如对比度线性拉伸)的影响。对于非线性的光照变化(如局部阴影导致的某些梯度幅值饱和), 算法还需对归一化后的向量进行阈值截断:将每个分量限制不超过 $0.2$,即 $f’_i = \min(f’_i, 0.2)$。 截断后,向量的长度不再是 1,因此需再次进行归一化:
$$\begin{equation} \mathbf{f}'' = \frac{\mathbf{f}'}{\|\mathbf{f}'\|_2} \end{equation}$$$0.2$ 的阈值意味着如果一个描述符的某个方向分量特别大,说明该处的梯度幅值受到了光照饱和的影响, 将其截断后重新归一化可以使描述符更加关注梯度的整体分布模式而非绝对的灰度强度,从而大幅提升对光照变化的鲁棒性。
至此,每个 SIFT 关键点都拥有了一个 128 维的描述符向量。该描述符综合了关键点的位置 $(x,y)$、尺度 $\sigma$、 主方向 $\theta$ 以及周围区域详细的梯度分布信息。
特征匹配
假设我们有基准图像 A 和待匹配图像 B。对于图像 A 中的每一个 128 维特征描述符向量, 我们需要在图像 B 的特征点数据库中寻找它的对应点。评判两个特征点相似度的可以计算它们 128 维向量之间的欧氏距离。 距离越小,说明这两个局部区域的纹理结构越相似。
但在高维空间(128维)中,仅靠全局的距离阈值来判断是不够的。因为不同的特征点本身的区分度不同,有些特征则容易和背景噪声混淆。
最近邻与次近邻距离比
Lowe 提出了一种相对比较法:对于图像 A 中的特征点 $P$,在图像 B 中找到距离它最近的特征点 $N_1$(距离为 $D_1$)。 继续在图像 B 中找到距离它第二近的特征点 $N_2$(距离为 $D_2$)。计算两者的距离比值:$Ratio = \frac{D_1}{D_2}$。
-
如果这是一个正确的匹配,那么最近邻 $N_1$ 应该是目标在另一张图上的真实投影,它的距离 $D_1$ 会非常小;而次近邻 $N_2$ 通常只是背景杂波中的一个相似干扰项,距离 $D_2$ 会相对较大。因此,比值 $D_1/D_2$ 会很小。
-
如果这是一个错误的匹配(比如特征点 $P$ 实际上是背景噪声,在图 B 中根本没有对应点), 那么图 B 中会有很多相似的干扰项聚集在相似的距离上, 导致 $D_1$ 和 $D_2$ 差不多大,比值 $D_1/D_2$ 会接近 1 。
Lowe 在大量真实图像上统计了概率密度函数(PDF),发现将比值阈值设定为 0.8 时,可以剔除掉 90% 的错误匹配, 只会误剔除不到 5% 的正确匹配 。即:
$$\text{If } \frac{D_1}{D_2} < 0.8 \implies \text{接受该匹配,否则剔除}$$图像拼接
得到匹配点后,想要进一步将两个图像拼接起来,需要估计单应矩阵 $H$,使第二幅图像映射到第一幅图像坐标系。 本次作业使用 RANSAC
\[3\]求解该矩阵,以降低误匹配对结果的影响。 最后将第二幅图像透视变换到第一幅图像坐标系,并在重叠区域做简单平均融合,从而得到最终的全景图像。
软件实现
本文程序实现位于 code/sift.py,整体由"特征提取"与"图像拼接"两部分组成。前者对应标准 SIFT 流程,后者使用自实现 SIFT 的输出完成两图配准和融合。为了减少重复 I/O,程序既支持直接传入图像路径,也支持传入灰度数组。
尺度空间与高斯差分
在代码层面,尺度空间部分由 gaussian_blur_image、create_initial_image、
build_gaussian_pyramid 与 build_dog_pyramid 四个函数完成。
-
gaussian_blur_image根据 $\sigma$ 动态生成核大小,近似遵循 $6\sigma+1$ 的经验规则, 因为用 Python 实现 for 循环效率实在过于缓慢,所以这里直接调用 OpenCV 的函数GaussianBlur完成卷积。 4{reference-type=“ref+label” reference=“fig:gaussian_blur_code”}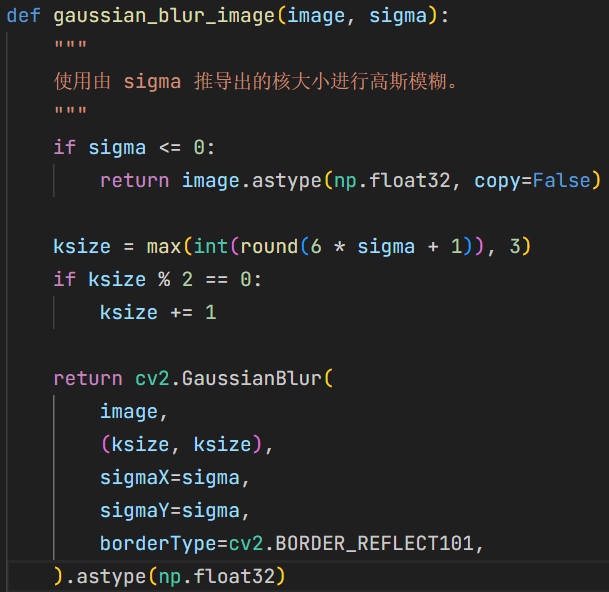
高斯模糊代码实现
-
create_initial_image先将输入图像放大 $2$ 倍,再利用高斯函数的半群性质补足到初始模糊尺度 $\sigma_0=1.6$, 与经典 SIFT 的做法保持一致。 5{reference-type=“ref+label” reference=“fig:create_initial_image_code”}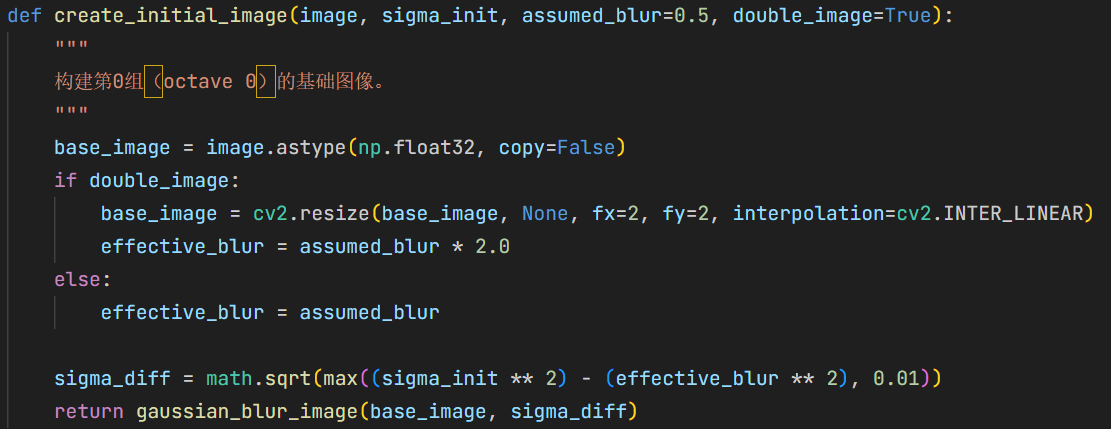
创建初始图像代码实现
-
build_gaussian_pyramid在每个 octave 内同样使用高斯函数的半群性质递推计算相邻层所需补充模糊量, 而不是每次从原图重新卷积,从而保证尺度关系正确。 6{reference-type=“ref+label” reference=“fig:build_gaussian_pyramid_code”}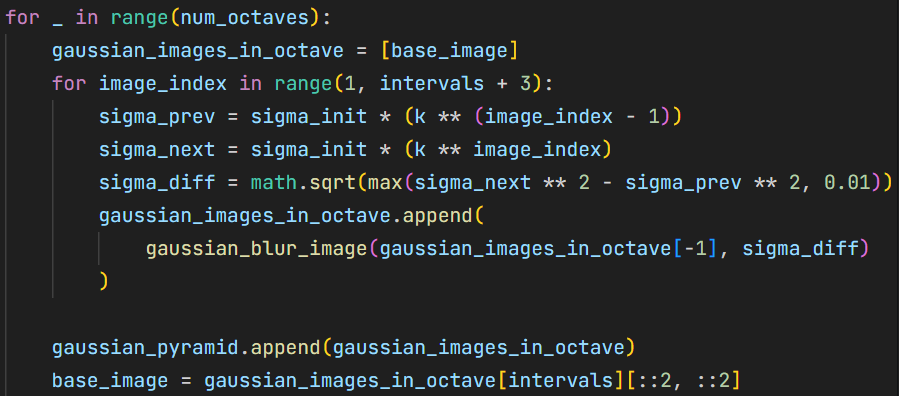
构建高斯金字塔代码实现
-
build_dog_pyramid直接对同一 octave 内相邻高斯层做减法,得到 DoG 图像序列。 7{reference-type=“ref+label” reference=“fig:build_dog_pyramid_code”}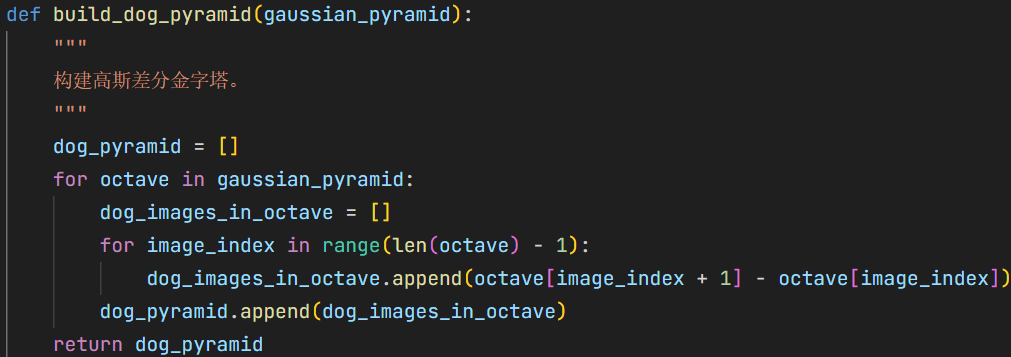
构建 DoG 金字塔代码实现
当前实现固定参数为 num_octaves = 4、num_intervals = 3、sigma_init = 1.6。
这一设置在图像上能够稳定提取较多特征,同时控制住运行时间。
关键点的精确定位与筛选
关键点检测由 is_pixel_an_extremum、localize_extremum_via_taylor 与
compute_keypoints 完成。
-
is_pixel_an_extremum对每个候选点做严格的 26 邻域比较,避免平台值进入候选集合。 注意,中心点可能为负数,此时需要看是否比周围的像素都小。 8{reference-type=“ref+label” reference=“fig:is_pixel_an_extremum_code”}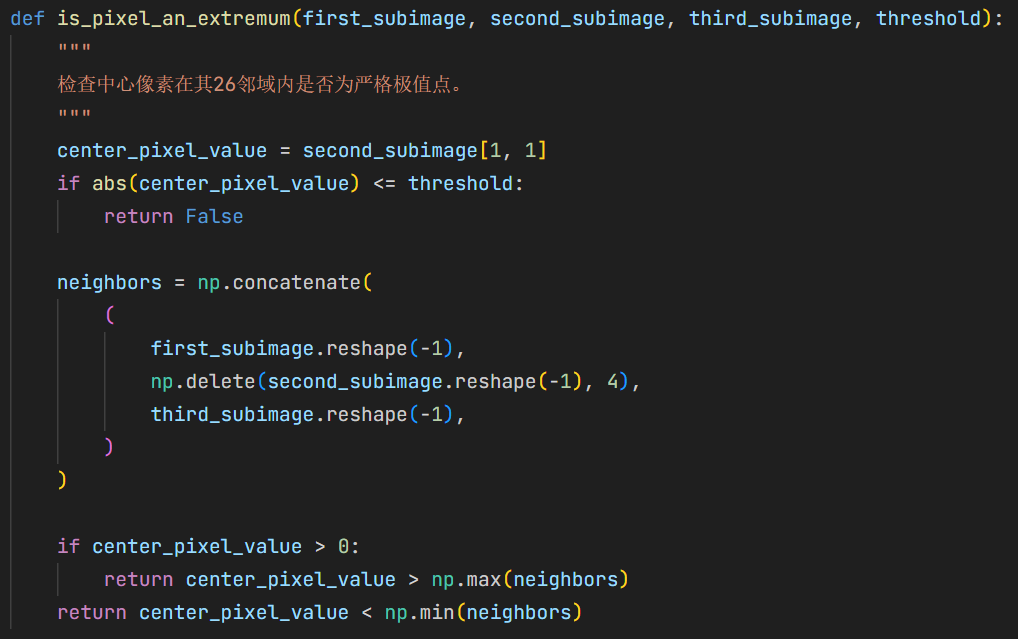
检查像素是否为极值点代码实现
-
localize_extremum_via_taylor负责计算梯度向量和 Hessian 矩阵, 并通过伪逆求解三维偏移量,因为 Hessian 矩阵可能非正定,所以需要使用伪逆而不是直接求逆。 对 $\sigma$ 方向求导并不是按照真实的 $\sigma$ 作为变量,而是以这个区域中的序号,即 $s$ 作为变量。 -
在精定位之后,代码按照论文思路先做低对比度剔除,再用二维 Hessian 主曲率比值剔除边缘响应点。
这一部分决定了最终关键点是否稳定,也是后续方向分配和描述子生成的基础。
方向分配
方向分配由 assign_orientations 完成。实现时有两个关键点。
-
梯度方向采用
atan2(dy, dx)的结果并映射到 $[0,360)$,与图像坐标系保持一致。 9{reference-type=“ref+label” reference=“fig:compute_gradient_and_orientation_code”}
计算梯度代码实现
-
在方向直方图形成后,先做一次高斯滤波。再做一次五点平滑,然后寻找局部峰值, 并使用抛物线插值计算更精确的峰值角度。 10{reference-type=“ref+label” reference=“fig:five-point_smoothing_code”}
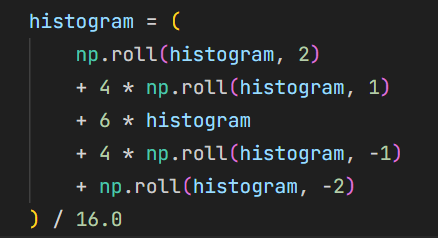
五点平滑代码实现
11{reference-type=“ref+label” reference=“fig:parabolic_interpolation_code”}

抛物线插值代码实现
如果某些次峰超过主峰的 $80%$,程序会为同一位置生成额外方向,这也解释了"稳定关键点个数"与"最终描述子个数"不相同。
局部图像描述符
描述子生成对应 generate_descriptor。该函数先根据关键点方向将局部窗口旋转到统一坐标系,
再将采样点投影到 $4\times 4$ 网格以及 8 个方向 bin 中。
程序使用三线性插值将每个采样点的贡献分配给最多 8 个相邻 bin,并采用"两次归一化 + 一次截断"的标准处理流程。
最终输出的每个描述子都是 128 维 float32 向量。
另外,程序内部关键点坐标是按放大后的基准图像计算的,因此在 compute_sift 返回结果前,
又调用 convert_keypoint_to_input_image_size 将坐标和尺度除以 2,
保证输出关键点与输入图像坐标保持一致。
特征匹配
描述子匹配由 match_descriptors 实现。为了避免依赖额外的 SciPy 距离函数,
代码采用 NumPy 矩阵运算直接构造平方欧氏距离矩阵:
然后对每一行找出最近邻和次近邻,再用比率测试决定是否保留该匹配,这里设置的比率阈阈值为 $0.75$。 相比双重循环逐点求距离,这样的实现更加紧凑,也便于后续扩展到更多特征点。 12{reference-type=“ref+label” reference=“fig:match_descriptors_code”}
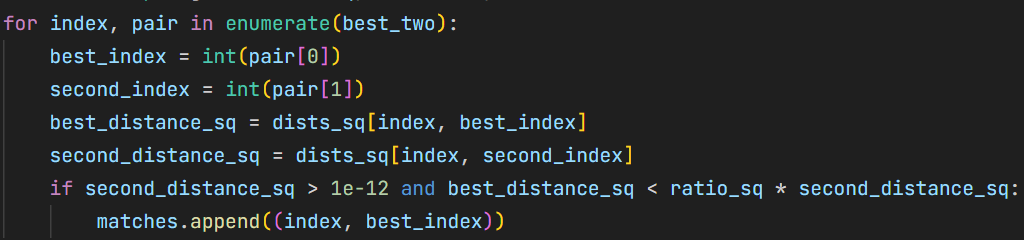
比率测试匹配描述子代码实现
图像拼接
拼接部分由 find_homography_ransac、warp_and_merge 和 stitch_images 组成。
-
find_homography_ransac调用 OpenCV 的cv2.findHomography函数, 根据匹配点估计从第二幅图像到第一幅图像的单应矩阵,确保矩阵方向与后续透视变换一致。 -
warp_and_merge先计算变换后四个角点的位置,确定最终画布大小,再对两幅图像进行透视映射, 并对重叠区域做均值融合。 -
stitch_images封装完整流程:读取彩色图像、转灰度提取 SIFT、比率测试、RANSAC、图像融合, 并将结果保存为code/figures/panorama.jpg。
这部分虽然只处理两张图像,但已经具备了从特征提取到几何估计再到输出全景图的完整闭环。
数据分析和可视化
关键点可视化
采用像素较小的图片 camera_man.png 进行关键点提取的调试。
结果如 13{reference-type=“ref+label” reference=“fig:keypoints_camera_man”} 所示。
可以看到,SIFT 提取的关键点数量很多,大部分是角点和边缘点,也有部分在草坪上突出的黑色板块周围。

原始图像

SIFT关键点可视化
关键点与匹配统计
实验使用两张已经缩放过的风景图像:YuejiangTowerLeft_resized.jpg 与
YuejiangTowerCenter_resized.jpg。
缩放版本的选择主要是考虑到当前 SIFT 实现中仍包含较多 Python 层循环,若直接使用原始大图,
运行时间会明显增长。拼接阶段采用的主要参数为:比率测试阈值 ratio_thresh = 0.75,
RANSAC 重投影阈值 reproj_thresh = 4.0,最大迭代次数 max_iters = 2000。
程序运行结果如下:第一张图像在方向分配前共有 694 个稳定关键点,经方向复制后生成 841 个最终特征;第二张图像分别为 704 个和 843 个。随后经过 Lowe 比率测试保留 30 对匹配点,经 RANSAC 筛选后得到 24 个内点。统计结果如 1{reference-type=“ref+label” reference=“tab:keypoints”} 与 2{reference-type=“ref+label” reference=“tab:matching”} 所示。
::: {#tab:keypoints} 图像 稳定关键点数 最终带方向特征数
Left_resized 694 841
Center_resized 704 843
: 两幅输入图像的 SIFT 特征统计 :::
::: {#tab:matching} 指标 数值
Lowe 比率测试后匹配数 30 RANSAC 内点数 24 内点率 80.0%
: 匹配与几何估计结果统计 :::
从统计上看,RANSAC 内点率达到 $24/30=80%$,说明比率测试保留下来的匹配中大部分都具备合理几何一致性,也说明当前实现提取到的特征具有较好的区分能力。
拼接结果可视化
最终全景图如 14{reference-type=“ref+label” reference=“fig:panorama_result”} 所示。可以看到,两幅图像在右侧主体、 树木边缘以及背景建筑等区域基本完成了基本对齐,但高楼却被错误的歪斜了,而且在建筑群和近处树木周围还有明显的重影现象。 说明基于 SIFT 的关键点匹配和单应矩阵估计是有效的,但照片的拍摄本身存在变焦、旋转、视差等干扰, 单纯的单应矩阵估计无法完全补偿这些因素。

原始左图

原始右图

使用自实现 SIFT、Lowe 比率测试与 RANSAC 得到的两图拼接结果
结果分析
结合特征统计与可视化结果,可以得到以下几点结论。
-
双倍基准图像与规范的初始模糊有助于提升小尺度特征的可检测性,因此最终关键点数量明显多于最初未修正版本。
-
主方向分配与描述子旋转坐标保持了统一的角度约定,使得特征在旋转情况下仍能稳定匹配,这是拼接成功的关键。
-
使用 NumPy 直接计算距离矩阵可以摆脱额外依赖,同时保证比率测试阶段的实现简洁可靠。
-
尽管结果已经能够成功拼接,但当前实现的主要瓶颈仍在描述子生成阶段的大量 Python 循环,因此运行速度偏慢。
-
融合阶段只做了平均叠加,没有使用羽化、多频段融合或曝光补偿,因此视觉质量仍有提升空间。
结论
本次作业基于 sift.py 完整实现了 SIFT 特征提取与两幅图像拼接流程。
程序按照经典方法完成了尺度空间构建、关键点精确定位与筛选、关键点方向分配、128 维描述子生成、
Lowe 比率测试以及 RANSAC 单应估计,并最终在风景图像上成功生成全景图。
从实验结果看,该实现已经具备较好的尺度和旋转鲁棒性,能够在两幅存在视角差异的图像之间建立可靠匹配关系, 并输出正确的拼接结果。与此同时,当前版本仍有两个明显不足:一是纯 Python 循环带来的运行速度较慢, 二是图像融合方式较为简单。后续若继续改进,可以考虑使用向量化方式重写局部梯度统计与描述子分配过程, 或使用 OpenCV 的更高效接口进行对照;在拼接部分,还可以加入双向一致性匹配、圆柱投影、羽化融合或多频段融合, 以进一步提升全景图的视觉效果。
:::::: {#refs .references .csl-bib-body entry-spacing=“0”} ::: {#ref-Lowe2004 .csl-entry} [
\[1\]]{.csl-left-margin}[D. G. Lowe, “Distinctive image features from scale-invariant keypoints,” International Journal of Computer Vision, vol. 60, no. 2, pp. 91–110, 2004]{.csl-right-inline} :::
::: {#ref-Harris1988ACC .csl-entry} [
\[2\]]{.csl-left-margin}[C. Harris and M. Stephens, “A combined corner and edge detector,” in Proceedings of the 4th alvey vision conference, 1988, pp. 147–151.]{.csl-right-inline} :::
::: {#ref-Fischler1981 .csl-entry} [
\[3\]]{.csl-left-margin}[M. A. Fischler and R. C. Bolles, “Random sample consensus: A paradigm for model fitting with applications to image analysis and automated cartography,” Communications of the ACM, vol. 24, no. 6, pp. 381–395, 1981]{.csl-right-inline} ::: ::::::